介绍
Jenkins 是一个开源的自动化服务器,广泛用于持续集成(CI)和持续交付(CD)的自动化流程。
本教程基于 docker 安装 Jenkins,需要掌握 docker 相关基础知识,且已经安装好 docker。
在 docker 上安装 Jenkins
打开终端,创建 bridge network
1
docker network create jenkins
为了在 Jenkins 节点内执行 Docker 命令,请使用以下 docker run 命令下载并运行 docker:dind Docker 镜像
1
docker run --name jenkins-docker --detach --privileged --network jenkins --network-alias docker --env DOCKER_TLS_CERTDIR=/certs --volume jenkins-docker-certs:/certs/client --volume jenkins-data:/var/jenkins_home --publish 2376:2376 docker:dind --storage-driver overlay2
自定义官方 Jenkins docker 镜像,通过以下步骤
- 创建一个 Dockerfile,加入下面的内容我这里使用了最新的 jenkins/jenkins:latest-jdk21,你也可以使用其他版本,不过 jenkins 目前只支持 jdk17 和 jdk21。
1
2
3
4
5
6
7
8
9
10
11
12
13FROM jenkins/jenkins:latest-jdk21
USER root
RUN apt-get update && apt-get install -y lsb-release ca-certificates curl && \
install -m 0755 -d /etc/apt/keyrings && \
curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc && \
chmod a+r /etc/apt/keyrings/docker.asc && \
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] \
https://download.docker.com/linux/debian $(. /etc/os-release && echo \"$VERSION_CODENAME\") stable" \
| tee /etc/apt/sources.list.d/docker.list > /dev/null && \
apt-get update && apt-get install -y docker-ce-cli && \
apt-get clean && rm -rf /var/lib/apt/lists/*
USER jenkins
RUN jenkins-plugin-cli --plugins "blueocean docker-workflow json-path-api"
如果这里镜像拉取失败,可以提前使用 docker pull 把需要的 jenkins/jenkins:latest-jdk21 拉取下来.
服务器上你可以使用阿里云的docker镜像加速,本地你可能需要科学上网了。
- 使用 docker build 基于上面的 Dockerfile 创建一个镜像,名称为
myjenkins-blueocean1
docker build -t myjenkins-blueocean .
- 使用下面的命令,将刚刚创建的 docker 镜像
myjenkins-blueocean运行为容器1
docker run --name jenkins-blueocean --restart=on-failure --detach --network jenkins --env DOCKER_HOST=tcp://docker:2376 --env DOCKER_CERT_PATH=/certs/client --env DOCKER_TLS_VERIFY=1 --publish 8080:8080 --publish 50000:50000 --volume jenkins-data:/var/jenkins_home --volume jenkins-docker-certs:/certs/client:ro myjenkins-blueocean
完成 Jenkins 基础配置
解锁 Jenkins
首次访问 http://localhost:8081/ 会出现一个需要解锁 Jenkins的页面,里面需要你输入管理员密码。
使用
1 | docker logs jenkins-blueocean |
查看运行日志,在两行*号之前有类似 7a3f82b6c4884ee19c8d6f48370a232c 这样的密码。
或者直接用命令提取
1 | docker exec jenkins-blueocean cat /var/jenkins_home/secrets/initialAdminPassword |
安装插件
作为新手,直接点击安装推荐的插件就行,然后等待它完成。
创建第一个管理员用户
需要创建一个管理员账户进行登录,需要账户、密码、邮箱,其他你可以不写。
创建完成直接保存,然后一直下一步,直到界面出现 欢迎来到 Jenkins!, 至此 Jenkins 基础配置就完成了。
配置前端项目
在 Jenkins 主页,点击 “新建Item”, 输入项目名称,选择 流水线(Pipeline) 类型。
点击配置,General 里面的 “This project is parameterized”, 给项目配置环境参数。
Choice Parameter 选项,配置变量名称 “BUILD_ENV”, 选项配置如下
1 | development |
写上中文描述,”请选择打包环境”。
在下面找到 **流水线(Pipeline)**,选择 “Pipeline Script”。
1 | pipeline { |
保存配置,找到之前配置的项目名称,如下图
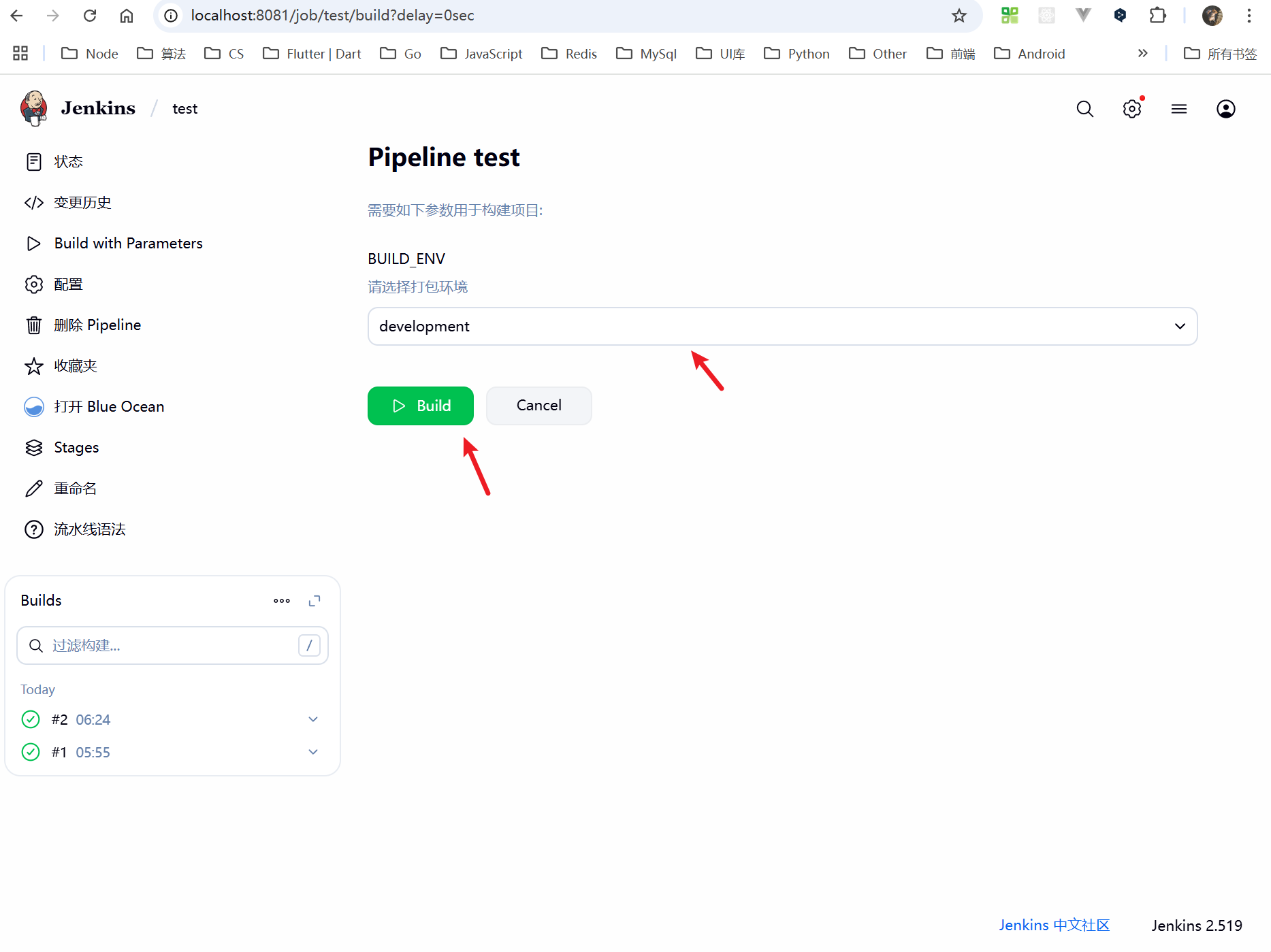
选择对应的环境,点击 “Build”。
点击左下角构建历史,绿色表示构建成功,红色表示构建失败。点击最近一次构建的记录,然后点击 “Console Output”, 查看详情内容。
一般最后出现 “Finished: SUCCESS” 就是构建成功了。
构建的时候,Pipeline Script 通过 docker:bind (Docker in Docker) 安装了 node 环境,执行 npm install,最后选择对应的环境执行 npm run build:dev等。
至此,前端的项目就构建完成,接下来,需要把打包的项目传到 nginx 静态目录就可以了。
